계층구조는 누가 관리하나?
- Registers <-> Memory : 컴파일러
- Cache <-> Memory : 하드웨어
- Memory <-> Disks : 하드웨어 & OS(VM), 프로그래머
메모리 계층 구조
Random Access
- 접근 시간이 모두 같을 때 좋은 선택
- DRAM: Dynamic Random Access Memory
- 고밀도, 저전력, 저렴, 느림
- SRAM: Static Random Access Memory
- 저밀도, 고전력, 비쌈, 빠름
- Static: 전력끊기 전까지 내용 유지
Main Memory(DRAM) + Caches (SRAM)
지역성 원리
1. Temporal Locality(시간적 지역성)
- 최근 access한 item은 조만간 다시 access 할 경향
2. Spatial Locality(공간적 지역성)
- 최근 access한 item 근처에 item이 조만간 다시 access 할 경향
지역성의 장점
- 메모리 계층 구조를 가짐.
- Disk에 모든것을 저장
- 최근 access된 item들은 idsk로부터 smaller DRAM memory(캐시메모리)로 Copy
- 더욱 최근 access된 item들은 DRAM으로부터 smaller SRAM memory로 copy
메모리 계층 구조
- Block : Copying 단위
- Hit: 만약 access 된 data가 upper level에 존재
- Miss : access 된 data가 없음.
- missPenalty(실패손실)
- access된 data는 upper level에서 공급됨.

DRAM 구조
DRAM은 셀에 기억되는 값이 전하 형태로 capacitor에 저장됨.
(SRAM은 전원이 공급되는 한 정보를 계속 저장)
DRAM의 캐퍼시터를 저장하기 위해 주기적으로 refresh가 필요.
refresh는 단순히 읽고 쓰는 것임.
매번 리프레시하면 접근할 시간이 없기 때문에 행 단위로 한꺼번에 처리함.

향상된 DRAM 구조
- DRAM의 비트는 배열로 저장됨.
- Burst Mode: row의 연속적인 word를 보내는 것 (latenct 줄임)
- Double Data Rate(DDR) DRAM
- rising & falling edge에 전달
- Quad Data Rate (DQR) DRAM
- DDR input과 output들을 분리
Memory Bandwidth
메모리 접근 순서
캐시 -> 메모리와 연결된 버스 -> 메모리
bandwidth(넓이)를 늘리면 이동가능한 메모리양이 늘어남
(고속도로를 넓힘)
bus를 늘리는 것은 비용이 많이들어 memory를 여러개로 나눈는 Memory Bank를 사용
(톨게이트를 늘림)

Cache
1. 캐시 안에 데이터가 있는 것을 어떻게 알 수 있나?
2. 어떻게 찾을 수 있나?
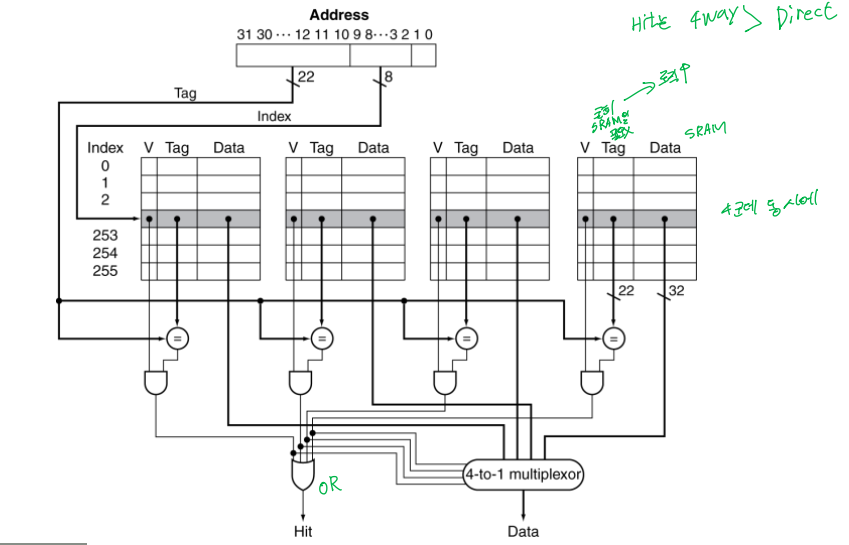
Direct Mapped Cache
- 위치가 address에 의해 결정
- Direct Mapped : 한 장소에 바로 mapped됨.

Valid bit: 해당하는 캐시에 데이터가 있는지 표시
Tag: 중복된 주소 중 어느 주소인지 확인
Address Subdivision

각 블록은 1워드(4byte)
Tag Size = 32 - 10(index) - 2
Example: Larger Block Size
64 blocks, 16 bytes/block
Block address = Lower(1200/16) = 75
Block number = 75 modulo 64 = 11

Block Size 고려사항
- Larger Block: miss rate를 줄임 (공간적 지역성)
- miss penalty가 커짐
Direct Mapped Cache
공간적 지역성 사용

하나의 워드가 미스가 나면, 한번에 갖다 놓기 때문에 다른 것들이 miss 날 것을 예방함
Cache Misses
cache hit 경우 : CPU 정상 작동
cache miss 경우
- stall the CPU pipeline(데이터가 없으므로 정지)
- Fetch block from next level of hierarchy
- Instruction cache miss (Restart instruction fetch)
- Data cache miss (Complete data access)
Write-Through
쓰기의 경우, 캐시에만 쓰고 메모리에 쓰지 않으면 데이터의 불일치 발생
이때, 해결하기 가장 쉬운 방법이 data가 바뀔때마다 같이 쓰는 방법 Write-Through(즉시 쓰기)

하지만 성능 저하가 심해질 수 있음.
예를 들어 명령어의 10%가 저장 명령어라고 가정
캐시 싶래가 없으면 CPI가 1.0이고 모든 쓰기에 100개의 추가 사이클 필요하다면,
CPI = 1.0 + 100 * 10% = 11 가 되므로 10배 이상의 성능 저하 발생
[ 해결책 ]
write buffer를 사용
- 데이터가 메모리에 써질 때까지 기다리는 동안 데이터를 저장
- CPU는 계속 진행됨 (write buffer가 full이 아닌 이상)
Write-Back
쓰기 발생 속도가 메모리가 받아들이는 속도보다 느려도 지연 발생 가능
-> 쓰기 폭주할 때 발생
- cache의 block에만 update
- Dirty block이 replace되는 경우
- 메모리에 다시 씀.
Main Memory Supporing Caches
메인 메모리르 위한 DRAM의 사용
- Fixed width
- Connected by fixed-width clocked bus
예를 들어
1 bus cycle for address transfer : 주소 보내기
15 bus cycles per DRAM access : 데이터 가져오기
1 bus cycle per data transfer : 데이터 다시 보내기
Miss Penalty = 1 + 4 * 15 + 4 * 1 = 65 bus cycles
Cache Performance Example
- 명령어 캐시 (I-cache) miss rate = 2%
- 데이터 캐시 (D-cache) miss rate = 4%
- Miss penalty = 100 cycles
- Base CPI (지연 없음) = 2
- Load & Stores 실행빈도 : 36%
Miss cycles per Instruction
- I-cache: 0.02 * 100 = 2
- D-cache: 0.36 * 0.04 * 100 = 1.44
Actual CPI = 2 + 2 + 1.44 = 5.44
Ideal CPI의 성능은 5.44/2 = 2.72배 더 좋아짐
Average Access Time
Average Memory Access Time (AMAT)
AMAT = Hit time + Miss Rate * Miss Penalty
예)
CPU 1ns clock, hit time = 1 cycle, miss penalty = 20 cycles, I-cache miss rate = 5%
AMAT = 1 + 0.05 * 20 = 2ns
성능 정리
- CPU 성능 증가 -> Miss penalty 증가
Associative Caches
1. Fully associative (완전 연관)
- 블록이 어느 곳에나 있을 수있어 주어진 블록을 찾으려면 캐시 내의 모든 엔트리 검색
- 따라서 매우 비쌈.
2. n-way set associative (집합 연관)
직접 사상과 완련 연관 사상의 중간 지대
- 각 set는 n개의 entry
- Block number는 어떤 set이 결정
- 선택된 set 내에서 아무곳에나 들어 갈수 있음.
- 따라서, 주어진 set에 대해 모든 enry를 검색
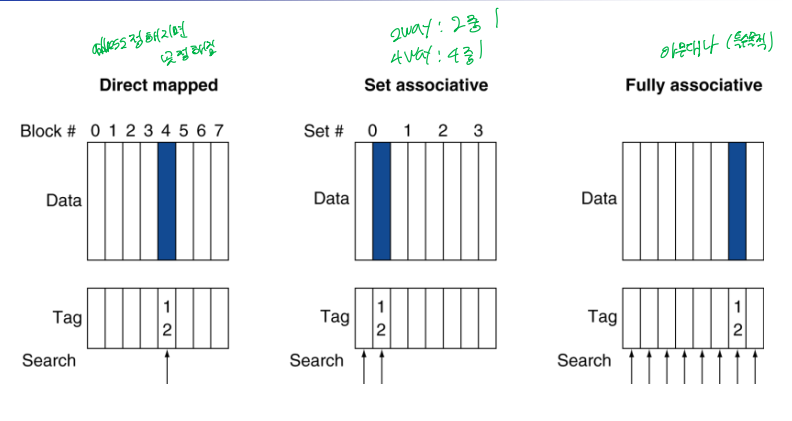

Associativity Example
1. Direct mapped

2. 2-way set associative

3. Fully associative
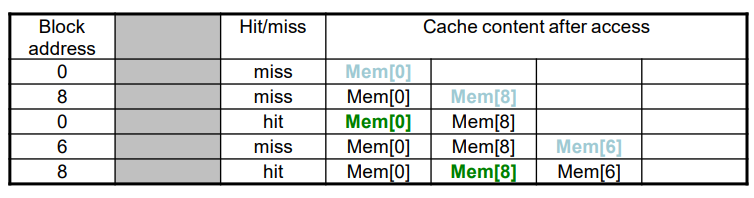
교체할 블록의 선택
- Direct mapped : 선택지가 없음
- Set associative
실패 발생 시, 요구된 블록을 어디에 넣을지 결정
- Non-valid entry가 있으면 사용
- 아니면, set에 있는 entry들에게 victim을 선정
이때 사용하는 방식이 LRU(least recently used)
- 가장오랫동안 사용하지 않는 것을 선택
Multilevel Caches
프로세서 클럭속도와 DRAM 접근시간 사이를 줄이기 위해, 2개의 캐시를 사용.
2차캐시: 마이크로프로세서와 같은 칩에 있다.
1차캐시: 실패가 발생하면 접근함. (*CPU에 attach됨)
L2캐시에 데이터가 있으면 실패손실은 main memory보다 훨씬 짧음.
High-end 시스템은 L3 캐시까지 포함한다.
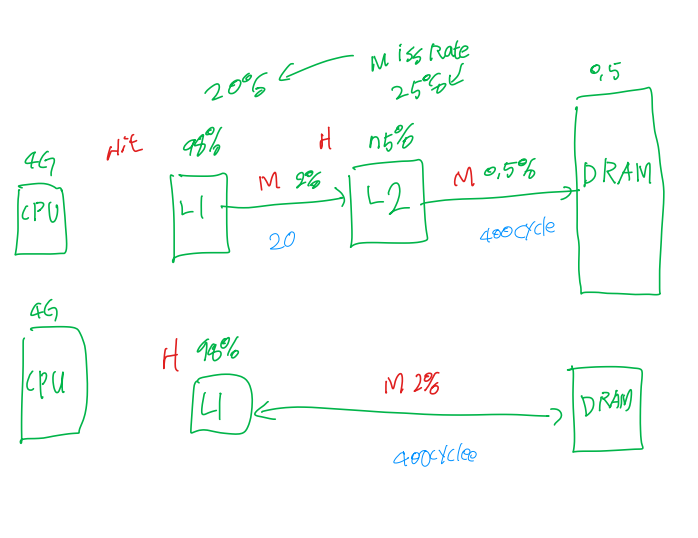
Multilevel Cache Example
- CPU base CPI = 1, clock rate = 4GHz
- Miss rate/instruction = 2%
- Main memory access time = 100ns
-> Miss penalty = 100ns/0.25ns = 400 cycles
-> Effective CPI = 1(기본 CPI) + 0.02 * 400 = 9
전체 CPI = 기본 CPI + 명령어 하나당 메모리 지연 사이클
이제 L2 캐시를 추가해보자
- Access time = 5ns
- Global miss rate to main memory = 0.5%
L2에서 miss penalty = 5ns/0.25 = 20 cycles
전체 CPI = 1 + 명령어 하나당 1차 캐시 지연 + 명령어 하나당 2차 캐시 지연
= 1 + 2% * 20 + 0.5% * 400 = 3.4
Performance ratio = 9/3.4 = 2.6
이를 그림으로 표현하면 다음과 같다.
Multilevel Cache Considerations
1. L1캐시 (Primary Cache)
- hit time을 최소화하는 것이 중요 (L1 에서는 Hit 발생 시, 빠르게 동작을 요구 받음)
2. L2캐시
- Main memory access를 줄이기 위해 low miss rate가 중요 (main memory 접근 시의 miss penalty 줄이기)
결론
- L1 캐시 크기가 작음
- L1 Block size는 L2 block size보다 작음
Interactions with Advanced CPU
대전제: 기존 CPU는 cache Miss 발생 시, pipeline이 정지됨
- Out-of-order CPU 는 cache miss 인 동안에도 실행됨.
- 유효 miss는 프로그램 데이터 플로우에 의존
Virtual Memory
- Main memory를 secondary storage의 "Cache"로 사용
- 프로그램들은 main memory를 공유
- 각 프로그램은 private virtual address space를 가짐
- 다른 program으로부터 Protected
- CPU와 OS는 virtual address를 physical address로 translate
- VM block 은 page라고 부른다.
- VM translation "miss" is called a page falult

가상 주소는 실제 주소가 어디인질 찾음
VA.space > PA.space -> 매핑이 다 안되는 주소는 Disk Address를 가르킴

[ 매핑하는 방법 ]
32 비트의 VA (4G) -> 28 비트의 PA (1G)
Translation : virtual page number(20bit) -> physical page number (18bit)
Page offset은 그대로 사용
Page Fault Penalty
VM에서 miss가 발생한 경우
- data가 memory에 없을 때 -> disk에 저장되어 있음
- penalty가 굉장이 큼
Page Table
- Placement information을 저장
- 만약 page가 main memory에 있으면, physical page number을 저장
- 만약 page가 main memory에 없으면, disk에 있는 swap space 위치를 참조

- virtual page number을 이용해 page table에서 physical page number을 찾아 실제 위치를 찾는다.

- Valid 가 0이면 Disk에 존재한다는 뜻 (Page Falut 발생)
Fast Translation Using a TLB
Page Table도 메모리에 존재하기 때문에, 접근시간이 소요된다,
따라서, 접근 속도를 해결하기 위해 Page Table을 위한 캐시를 작게 만들어 사용
TLB: address translation(Page Table)을 위해 캐시

[ 참고 ]
https://velog.io/@blacklandbird/%EC%BB%B4%ED%93%A8%ED%84%B0%EA%B5%AC%EC%A1%B0-8
컴퓨터 구조 8
컴퓨터의 기본 구조는 메모리에서 코드를 가지고오고 LW, SW연산을 통해 메모리의 데이터를 저장하거나 읽어오는것이다. 주소에 대한 읽기 쓰기가 실행된다. 하나의 프로그램이 모든 논리주소체
velog.io
'🏫학부 공부 > 컴퓨터구조' 카테고리의 다른 글
| [컴구] 프로세서 - 2 (0) | 2023.11.21 |
|---|---|
| [컴구] 프로세서 - 1 (0) | 2023.11.16 |
| [컴구] Multiplication and Division (0) | 2023.10.21 |
| [컴구] 컴퓨터 추상화와 기술 (0) | 2023.10.21 |
| [컴구] 연산자와 피연산자 (0) | 2023.10.11 |



