Pipelining

- Non-stop: 2n/0.5n + 1.5 = 4
MIPS Pipeline Step
1. IF: Instruction Fetch from Memoty
2. ID : Instruction Decode & Register Read
3. EX : Execute Opration or Calculate Address
4. MEM : Access Memoty Operand
5. WB : Write Result Back to Register
Pipeline 성능
[ 가정 ]
- register Read, Write : 100ps
- other : 200ps
위 표를 토대로 Single-Cycle과 Pipelined를 비교해보자.
- Pipelined가 더 빠른 것을 쉽게 알 수 있음.
[ 시간 계산 ]
- 모든 Stage가 같은 시간이 걸림(balanced)
Time(pipelined) = Time(nonpipelined) / stage_number
- balanced가 아니면, 속도 상승이 줄어듬.
Pipelining and ISA Design
MIPS ISA는 파이프라인화 하기 위해 설계되었다.
1. 모든 명령어는 32비트 (Fetch와 Decode가 1 Cycle에 처리 용이)
2. 소수의 명령어 형식 (R, I, J)
3. Load/Store Addressing
4. Memory Oprerand의 alignment (Memory Access가 1 Cycle에 수행 가능)
Hazards
: Next Cycle에서 Next Instruction이 시작되는 것을 방해하는 상황
총 세가지의 Hazard
1. Structure hazards: 리소스 개수의 부족
2. Data hazard : 이전 명령어의 data를 사용해야 하는 경우
3. Control Hazard : 이전 명령어의 결과에 의존적인 경우
1. Structure Hazards
- Resource Conflict에 의해 발생
예) Single Memory의 MIPS pipeline의 경우
- Load/Store는 Data Access가 필요함
- Instruction Fetch 시, 리소스 충돌이 발생해서 stall cycle(Bubble) 발생 가능
- 따라서, pipelined datapath은 별도의 instruction/data Memory(또는 Caches)가 필요
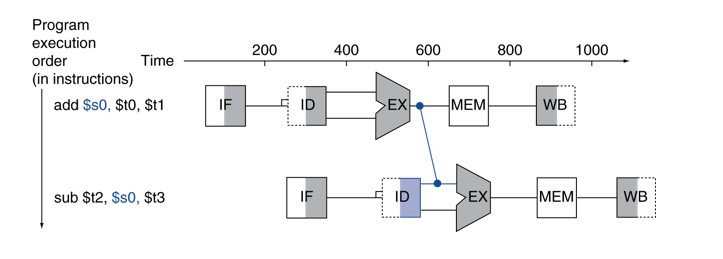
2. Data Hazard
add $s0, $t0, $t1;
sub $t2, $s0, $t3;
위 명령어를 실행할 경우, add에서 $s0에 저장되기 전 sub애소 $s0이 사용되기 때문에 오류가 날 수 있다!
위 경우 처럼 2사이클의 Bubble을 추가해야한다!
해결책: Forwarding(혹은 Bypassing)
: 결과가 나오면 이를 바로 사용
- 결과가 register에 store될때까지 기다리지 않아도 됨.
- 대신, 추가 connection이 필요
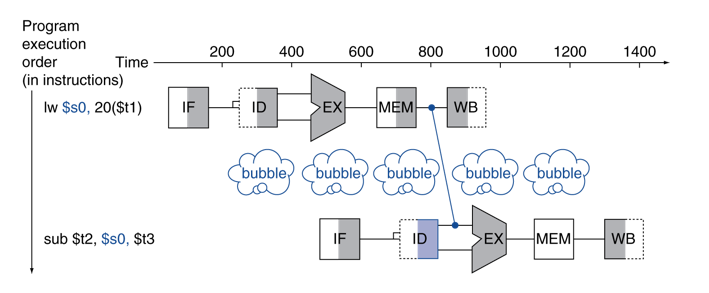
Load-User Data Hazard
- 그러나 Forwarding으로 stall을 할 수 있는 것은 아님.
- lw의 경우 memory에 접근이 필요하기 때문에, 1 싸이클의 버블이 발생한다.
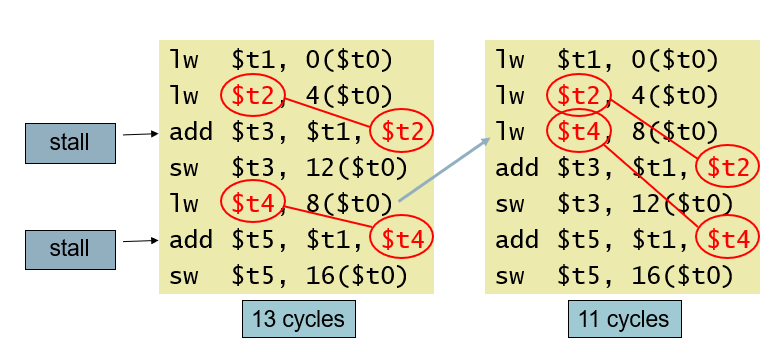
파이프라인 지연을 피하기 위한 코드 재정렬
코드의 순서를 바꿔서 stall이 발생하지 않도록 막는다.
= load result를 다음 명령어에서 사용되는 것을 방지
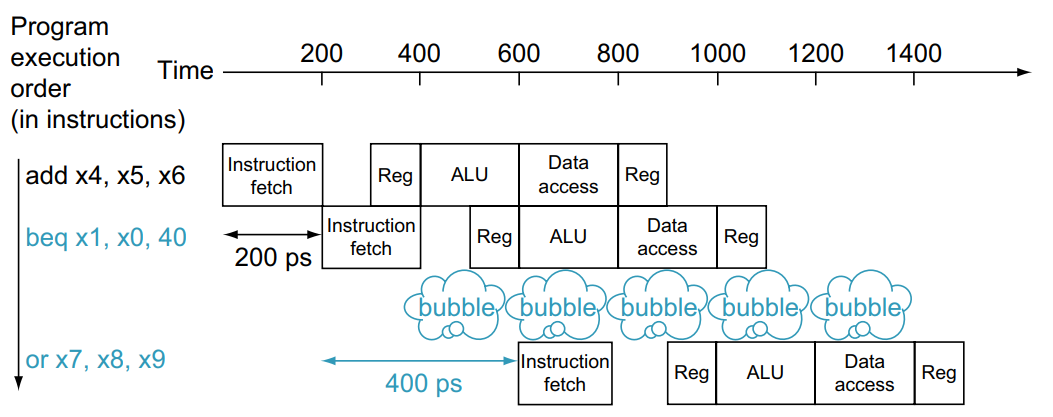
3. Control Hazard
- 다른 명령어들이 실행되는 동안 어떤 명령어의 결과에 기반을 둔 경정을 할 필요가 있을 경우
- Conditional Branch로 PC 값을 바꿀 때, 이미 Pipeline에 들어와있는 명령어가 실행되는 경우
즉, pipeline에 이미 반입된 다음 명령어들을 버려야 한다.
예)
a = b + c
d = f + a <- 위 코드가 종료되야 실행 가능
### 해결책: Stall on Branch
다음 명령어를 Fetch하기 전에 branch 결과가 나올때까지 기다리기
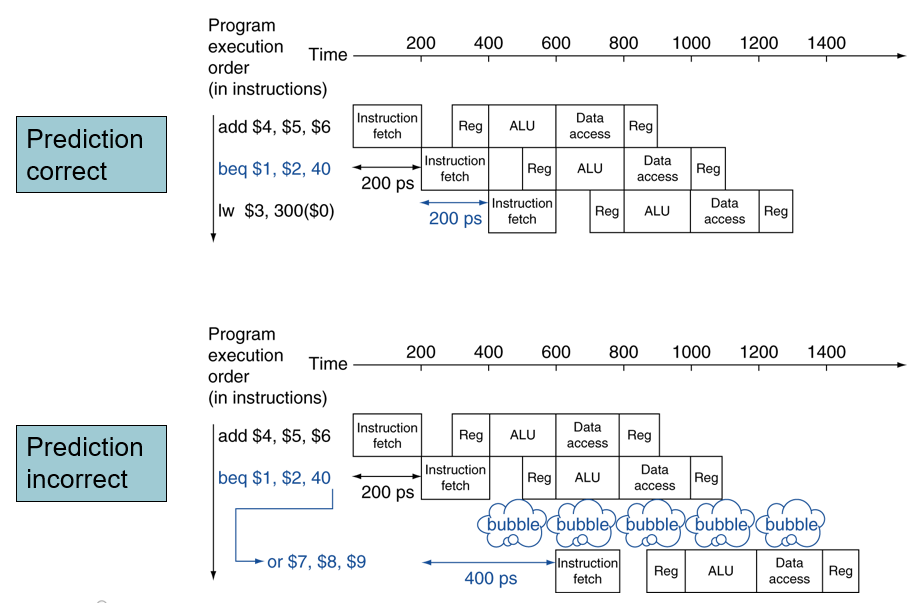
Branch Prediction
위 사례에선 1사이클의 wait만 하면되지만, 만약 파이프라인이 20 사이클이고 중간에 wait를 하면 10 사이클을 wait해야해서 비효율적.
그래서 Prediction을 통해 Branch가 taken될지, not taken될지 예측한다.
MIPS에선 Prediction이 Wrong 일 때만 wait한다.
[ Branch Prediction 종류 ]
1. Static Branch Prediction
- typical branch behavior 기반
- 예) loop, if-statment branches
2. Dynamic Branch Prediction
- Hardware가 actual branch behavior를 측정 ( 예: 최근 branch history 기록)
- Future behavior가 측정된 trend를 지속할 것을 가정 (틀렸을 때, re-fetching 또는 update history 될 동안 stall함)
- Clock 주파수의 영향을 받지 않음.
Pipeline Registers
stage들간에 register가 필요함. -> 이전 사이클에 생성된 정보를 Hold하기 위해서
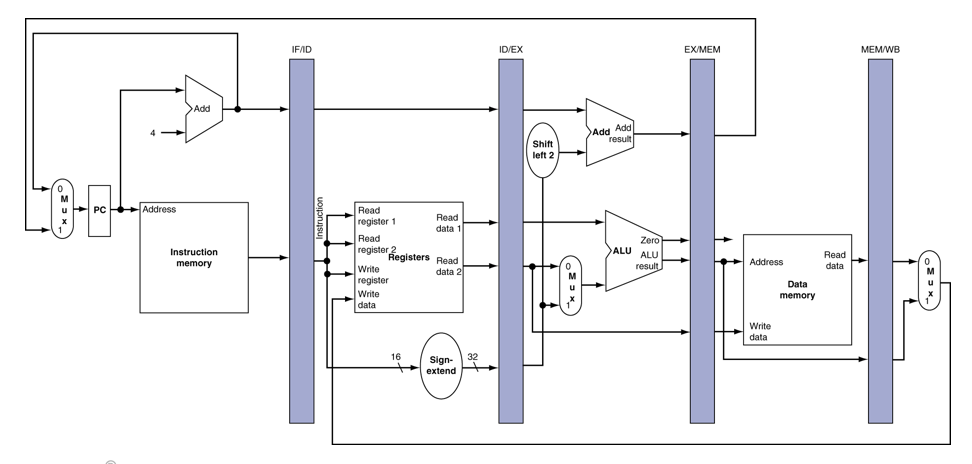
Pipeline Operation
Single-clock-cycle 파이프라인에서 load&store 명령어의 수행 과정을 보자
IF (Load, Store)
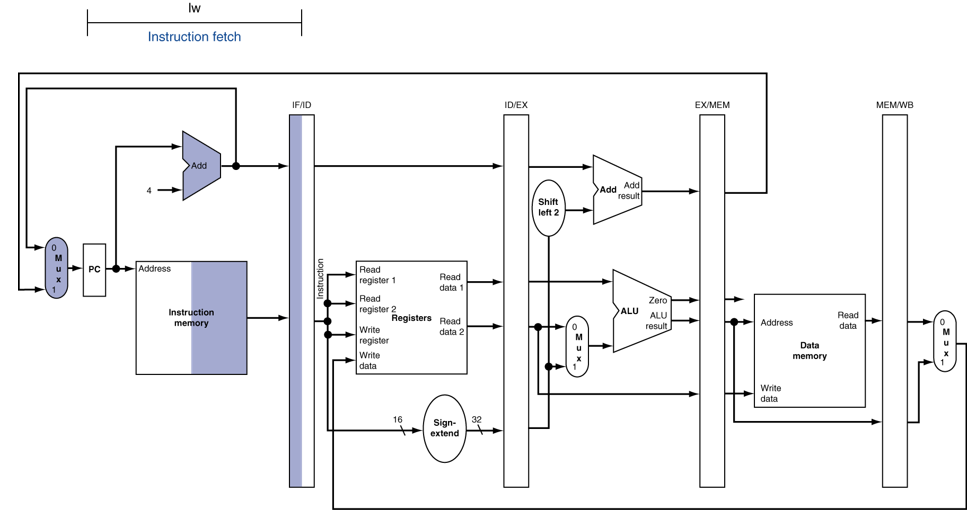
ID (Load, Store)
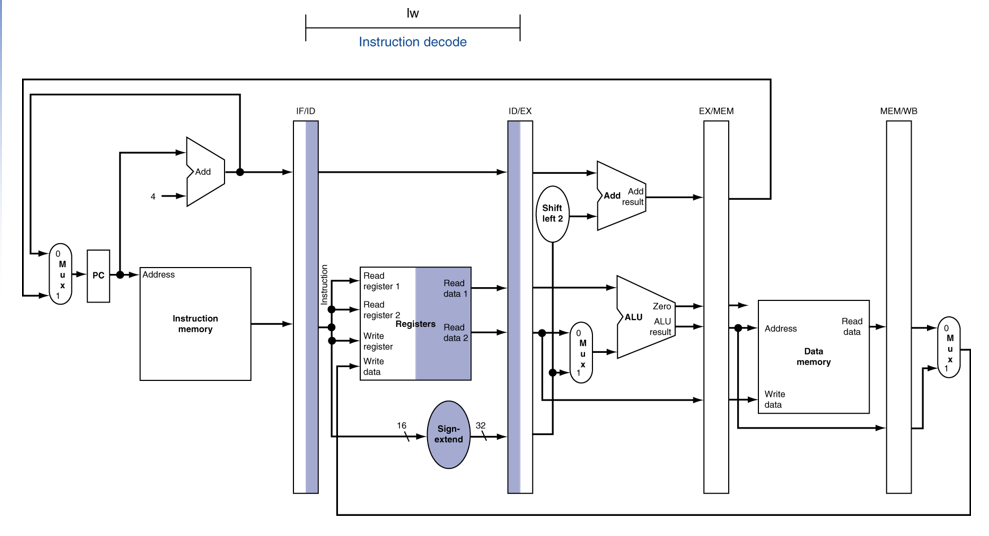
EX(Load)
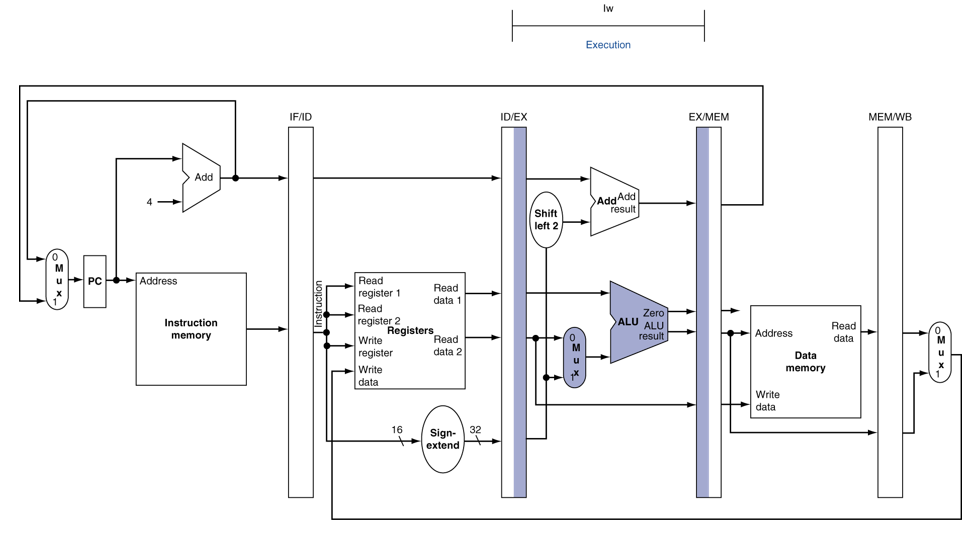
MEM (Load)
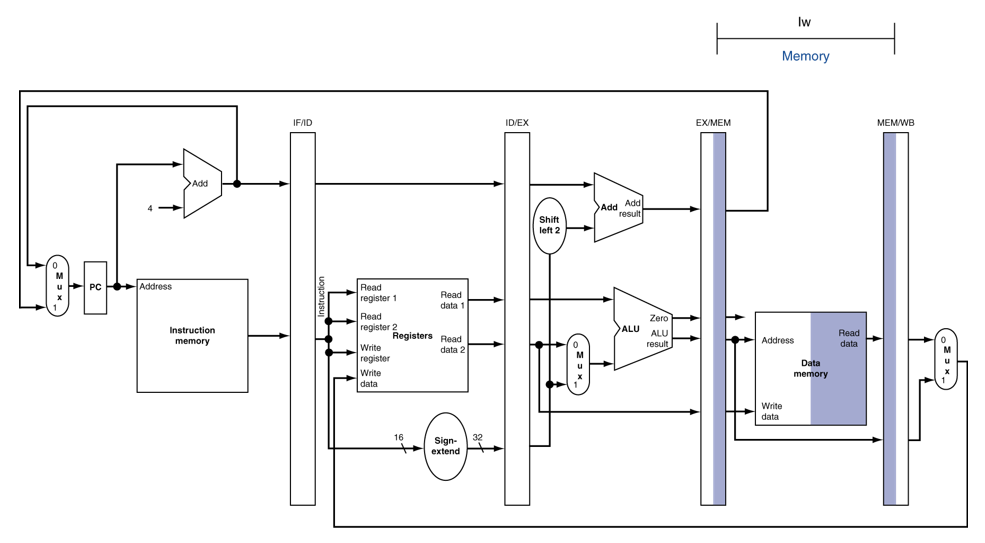
WB (Load)
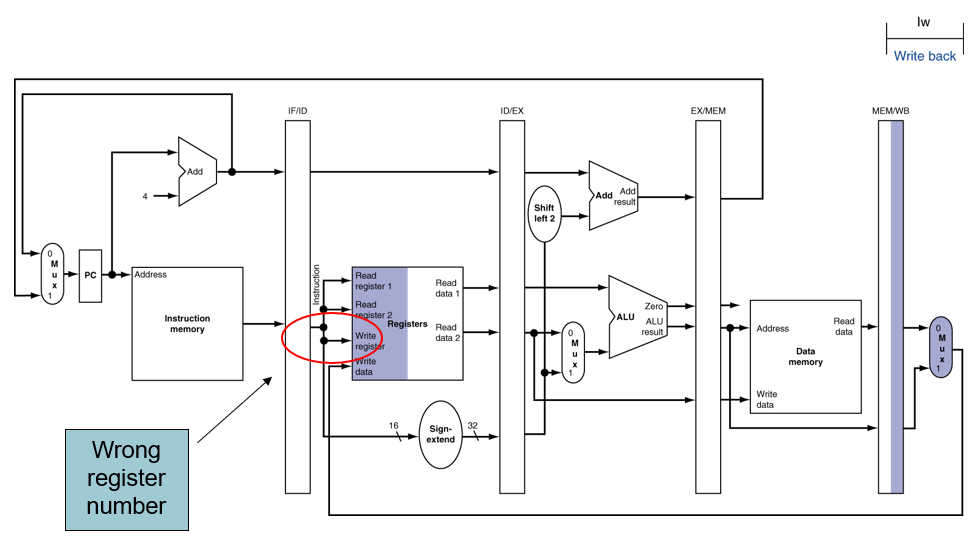
rd에 값을 저장해야 한다. 그러나 이미 1사이클이 돌아버렸기 때문에 기존에 있던 Instruction 정보들이 말소 되었다.
그래서, 해당 명령어를 각 stage 마다 가지고 다니면서 추후에 사용하도록 수정할 수 있다.
Multi-Cycle Pipeline Diagram
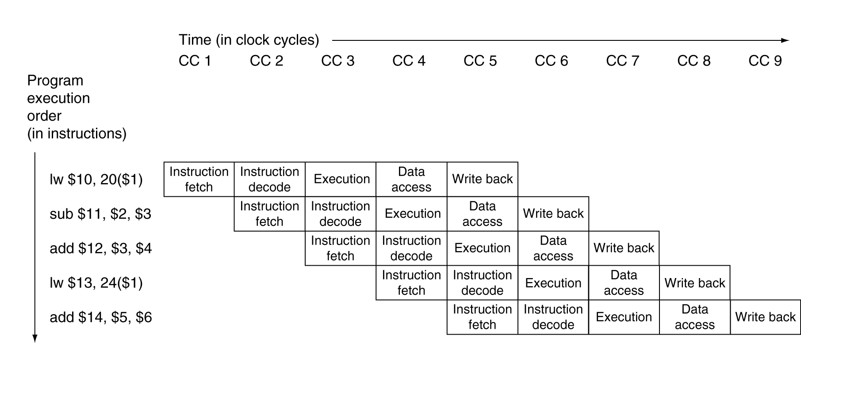
Pipelined Control
모든 Control siganl들은 Instruction에서 도출됨.
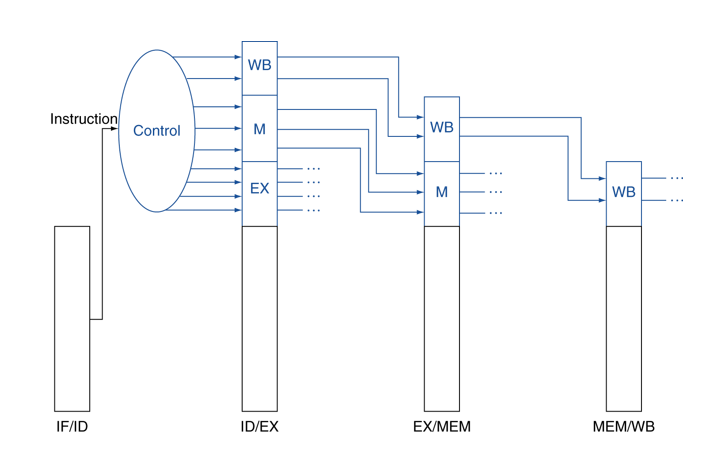
## Pipelined Control
Datapath with Contorl에 끌고 다니는 wire 추가
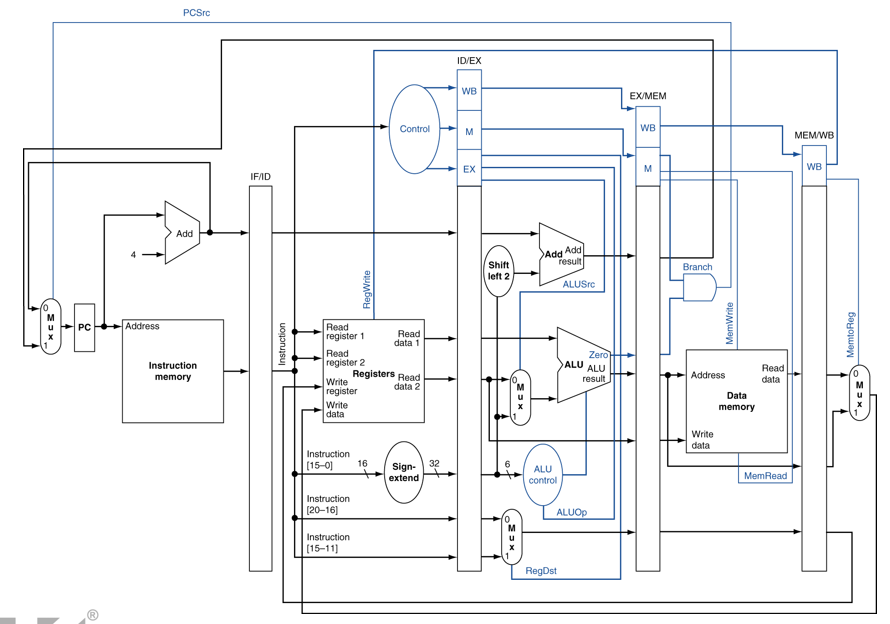
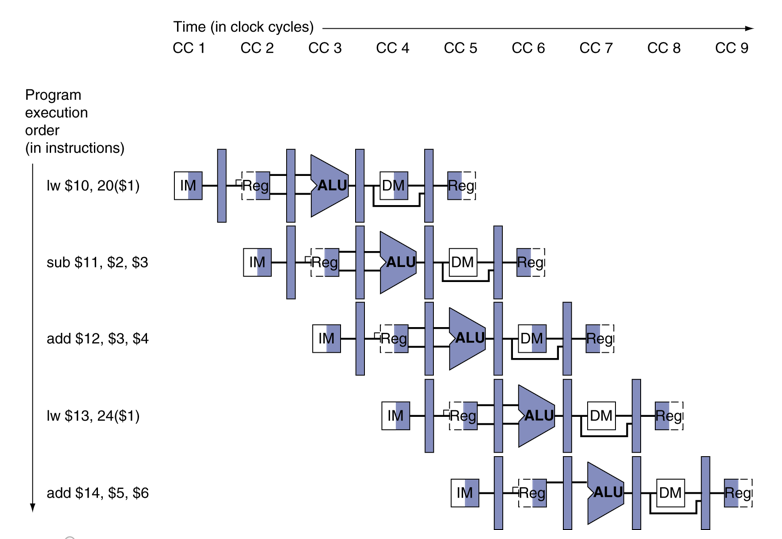
# Data Hazards in ALU Instructions
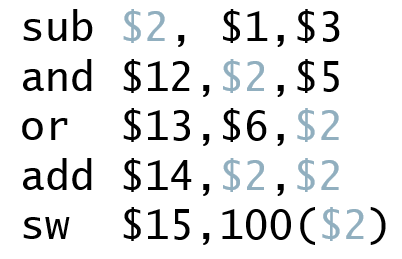
다음 명령어에서 Data Hazard가 발생한다. 이를 Forwarding으로 해결하려면 언제 할지 검사해야함.
## Dependencies & Forwarding
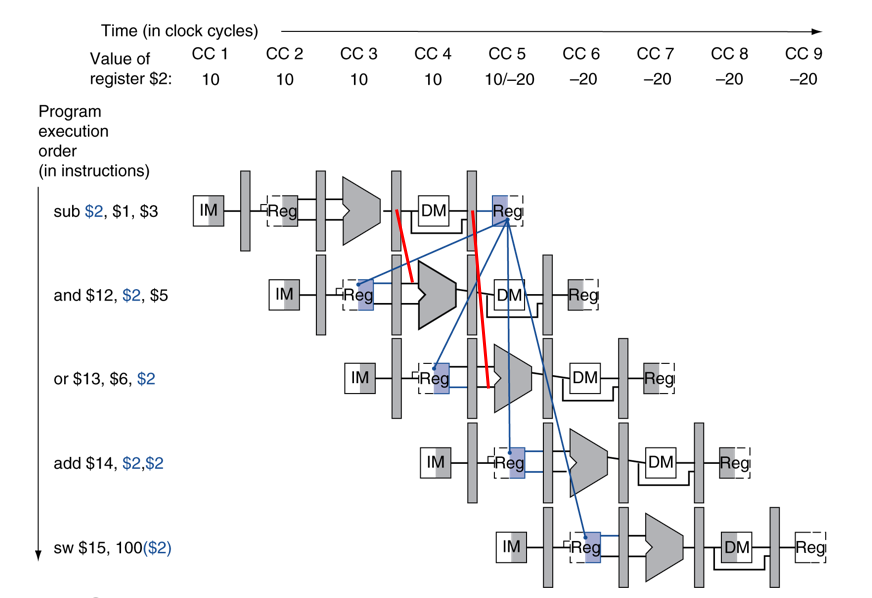
add, sw는 기존처럼 Forwarding해도 상관이 없지만, and와 or은 빨간색으로 이전에서 바로 뽑아줘야 사용가능함.
이때의 조건을 식으로 작성

1a와 1b는 바로 이전의 stage와 의존성이 발생한 경우. (sub -> and)
2a와 2b는 이전 이전의 stage와 의존성이 발생한 경우. (sub -> or)
추가로 다음 Register에 데이터를 write하는 경우도 추가해준다.
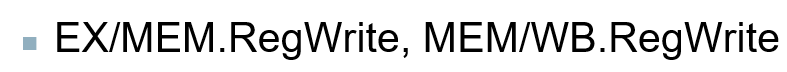
## Forwarding Paths
Forwarding의 경로를 보자.
### Forwarding Conditions
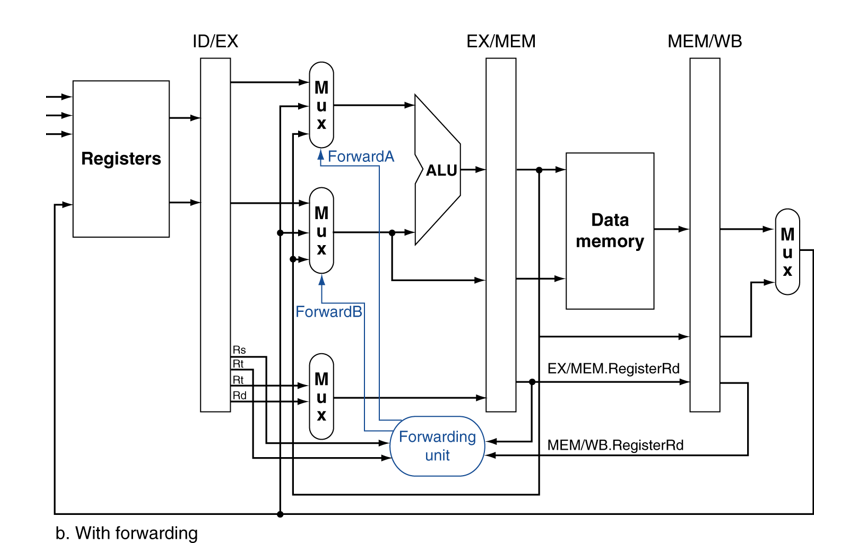
[ EX Hazard ]
if (ID/EX.RegWrite & (EX/MEM.Rd == ID/EX.Rs)) ForwardA = 10
if (ID/EX.RegWrite & (EX/MEM.Rd == ID/EX.Rt)) ForwardB = 10
[Mem Hazard ]
if(Mem/WB.RegWrite & (MEM/WB.Rd == ID/EX.Rs)) ForwardA = 01
if(Mem/WB.RegWrite & (MEM/WB.Rd == ID/EX.Rt)) ForwardB = 01
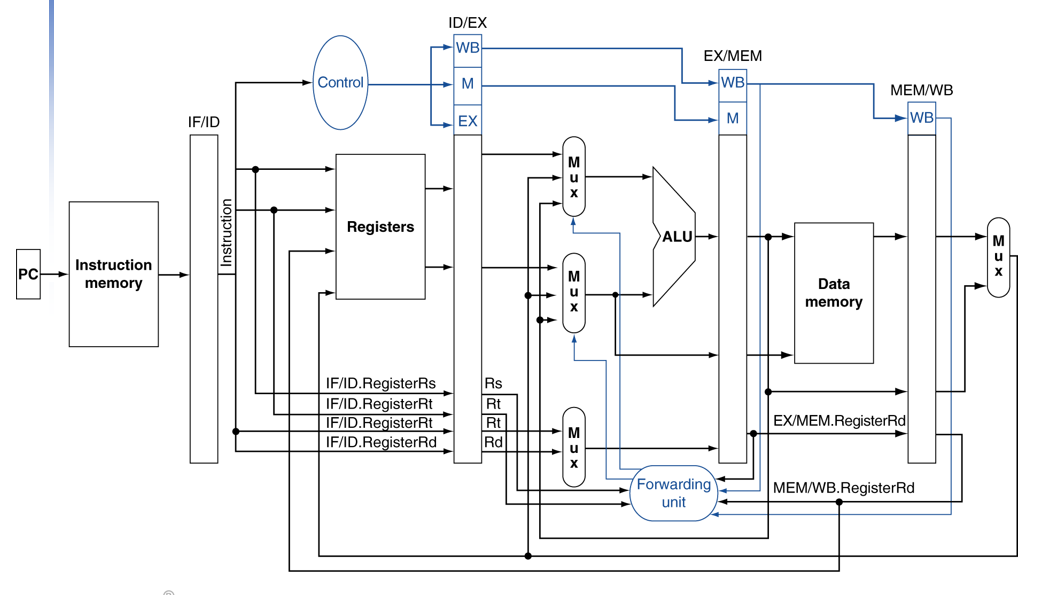
# Load-Use Data Hazard
Forwarding으로 해결 할 수 없는 경우, 버블을 이용해야 함
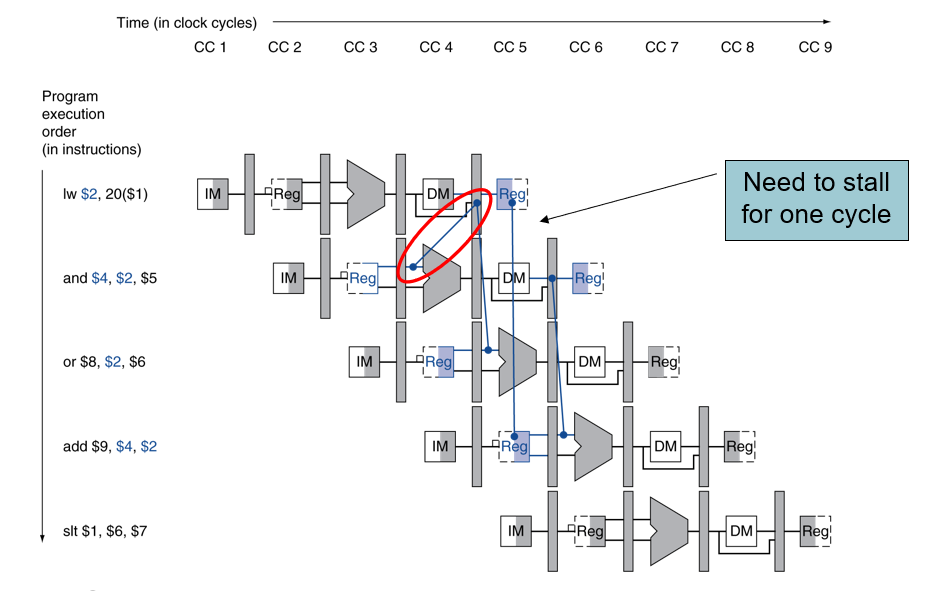
## Load-Use Hazard 조건
if(ID/EX.MemRead & (ID/EX.Rt = IF/ID.Rs) || (ID/EX.Rt = IF/ID.Rt))
- detect되는 경우, stall 발생하여 bubble을 삽입
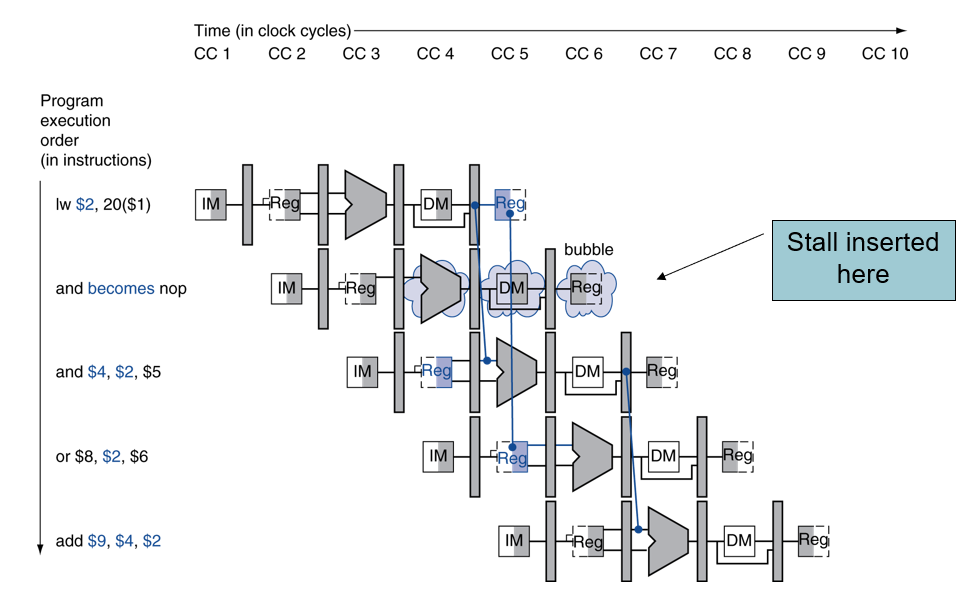
and 명령어 부터 한 사이클씩 밀리게 된다.
이를 데이터 패스로 보면 다음과 같다.
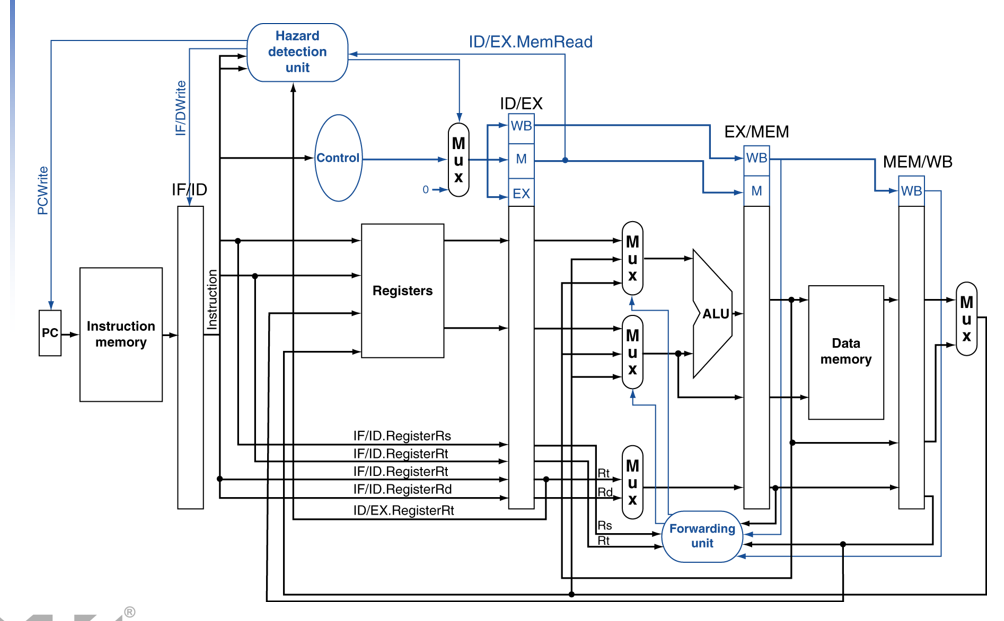
# Dynamic Branch Prediction
- 슈퍼 스칼라: 스칼라 명령어들 중 동시에 실행가능한 명령어들을 동시에 실행
- superscalar pipeline에선 branch penalty가 중요
# Multiple Issue
1. Static Multiple Issue
- 컴파일러가 같이 내보낼 명령어를 묶어서 내보냄. 주체: 컴파일러
2. Dynamic Multiple issue
- CPU가 매 사이클 명령어를 고르고, Stream을 조정
- 컴파일러가 명령어 순서를 조정함.
## Dynamically Scheduled CPU
1. 명령어르 가져오고 해독
2. 각 해독된 명령어는 대기영역으로 들어가서, 피연산자 올때까지 보류
3. functional unit에서 명령어에 맞게 실행되고 결과는 out-of-order
4. Commit 에서 실행된 결과를 실제 레지스터에 반영
out-of-order execution : 프로그램 데이터 흐름 순서를 바꾸지 않는 범위 내에서 명령어 실행 순서를 변경
[ 참고 ]
https://hi-guten-tag.tistory.com/267
[컴퓨터 구조] Control Hazard
앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.11.10 - [Computer Science/컴퓨터 구조] - [컴퓨터 구조] Hazard [컴퓨터 구조] Hazard 앞의 글을 읽으시면 이해에 도움이 됩니다. 2022.11.10 - [Computer Science/컴퓨
hi-guten-tag.tistory.com
'🏫학부 공부 > 컴퓨터구조' 카테고리의 다른 글
| [컴구] 메모리 계층구조 (0) | 2023.12.13 |
|---|---|
| [컴구] 프로세서 - 1 (0) | 2023.11.16 |
| [컴구] Multiplication and Division (0) | 2023.10.21 |
| [컴구] 컴퓨터 추상화와 기술 (0) | 2023.10.21 |
| [컴구] 연산자와 피연산자 (0) | 2023.10.11 |



